Chroma: One of the best vector databases to use with LangChain for storing embeddings
The LangChain framework allows you to build a RAG app easily. In this tutorial, see how you can pair it with a great storage option for your vector embeddings using the open-source Chroma DB.

Introduction
When it comes to choosing the best vector database for LangChain, you have a few options. In this post, we're going to build a simple app that uses the open-source Chroma vector database alongside LangChain to store and retrieve embeddings.
We're going to see how we can create the database, add documents, perform similarity searches, update a collection, and more.
So, without further ado, let's get to it!
What is LangChain?
LangChain is an open-source framework designed to help developers build AI-powered apps using large language models (or LLMs). It primarily uses chains to combine a set of components which can then be processed by a large language model such as GPT.
LangChain lets you build apps like:
- Chat with your PDF
- Convert text to SQL queries
- Summarization of videos
- And much more...
What are vector embeddings?
Vector Embeddings are numerical vector representations of data. They can include text, images, videos, and other types of data.
Vector Embeddings can be used for efficient querying operations such as:
- Similarity Search
- Anomaly Detection
- Natural Language Processing (NLP) Tasks
So where do we store vector embeddings? In a traditional SQL database? A NoSQL database? In a flat file? Just like traditional databases handle the storing of structured data efficiently, we need specialized databases built to handle vector embeddings.
There are many popular and well-tested vector databases besides Chroma including (but not limited to) Pinecone, Milvus, and Weaviate. However, for this post, we're going to focus on Chroma.
What is Chroma?

Chroma (commonly referred to as ChromaDB) is an open-source embedding database that makes it easy to build LLM apps by storing and retrieving embeddings and their metadata, as well as documents and queries.
The AI-native open-source embedding database - https://www.trychroma.com/
While there are plugins such as Postgres's pgvector and sqlite-vss that enable vector storage using traditional SQL databases, Chroma is optimized and was primarily built to work with LLM apps making it a great option to use exclusively or alongside your existing SQL or NoSQL database.
Here's a typical workflow showing how your app uses Chroma to retrieve similar vectors to your query:

Chroma officially supports Python and JavaScript via native SDKs. However, there is community support for other languages such as C#, Java, and others. For a full list, see this.
Building our app
Okay, all good so far? Great! Let's build our demo app which will serve as an example if you're planning on using Chroma as your storage option. We're going to build a chatbot that answers questions based on a provided PDF file.
We'll need to go through the following steps:
- Environment setup
- Install Chroma, LangChain, and other dependencies
- Create vector store from chunks of PDF
- Perform similarity search locally
- Query the model and get a response
Step 1: Environment setup
Let's start by creating our project directory, virtual environment, and installing OpenAI.
Grab your OpenAI API Key
Navigate to your OpenAI account and create a new API key that you'll be using for this application.

Set up Python application
Let's create our project folder, we'll call it chroma-langchain-demo:
mkdir chroma-langchain-demoLet's cd into the new directory and create our main .py file:
cd chroma-langchain-demo
touch main.py
(Optional) Now, we'll create and activate our virtual environment:
python -m venv venv
source venv/bin/activate
Install OpenAI Python SDK
Great, with the above setup, let's install the OpenAI SDK using pip:
pip install openaiStep 2: Install Chroma & LangChain
Installing Chroma
We'll need to install chromadb using pip. In your terminal window type the following and hit return:
pip install chromadbInstall LangChain, PyPDF, and tiktoken
Let's do the same thing for langchain, tiktoken (needed for OpenAIEmbeddings below), and PyPDF which is a PDF loader for LangChain. We'll also use pip:
pip install langchain pypdf tiktokenStep 3: Create a vector store from chunks
Download and place the file below in a /data folder at the root of your project directory (Alternatively, you could use any other PDF file):
This should be the path of your PDF file: chroma-langchain-demo/data/document.pdf.
In our main.py file, we're going to write code that loads the data from our PDF file and converts it to vector embeddings using the OpenAI Embeddings model.
Use the LangChain PDF loader PyPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings.openai import OpenAIEmbeddings
loader = PyPDFLoader("data/document.pdf")
docs = loader.load_and_split()Here we use the PyPDFLoader to ingest our PDF file. PyPDFLoader loads the content of the PDF and then splits the it into chunks using the load_and_split() method.
Pass the chunks to OpenAI's embeddings model
Okay, next we need to define which LLM and embedding model we're going to use. To do this let's define our llm and embeddings variables as shown below:
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.8)
embeddings = OpenAIEmbeddings()Using the Chroma.from_documents, our chunks docs will be passed to the embeddings model and then returned and persisted in the data directory under the lc_chroma_demo collection, as shown below:
chroma_db = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="data",
collection_name="lc_chroma_demo"
)Let's look at the parameters:
embedding: lets LangChain know which embedding model to use. In our case, we're usingOpenAIEmbeddings().persist_directory: Directory where we want to store our collection.collection_name: A friendly name for our collection.
Here's what our data directory looks like after we run this code:
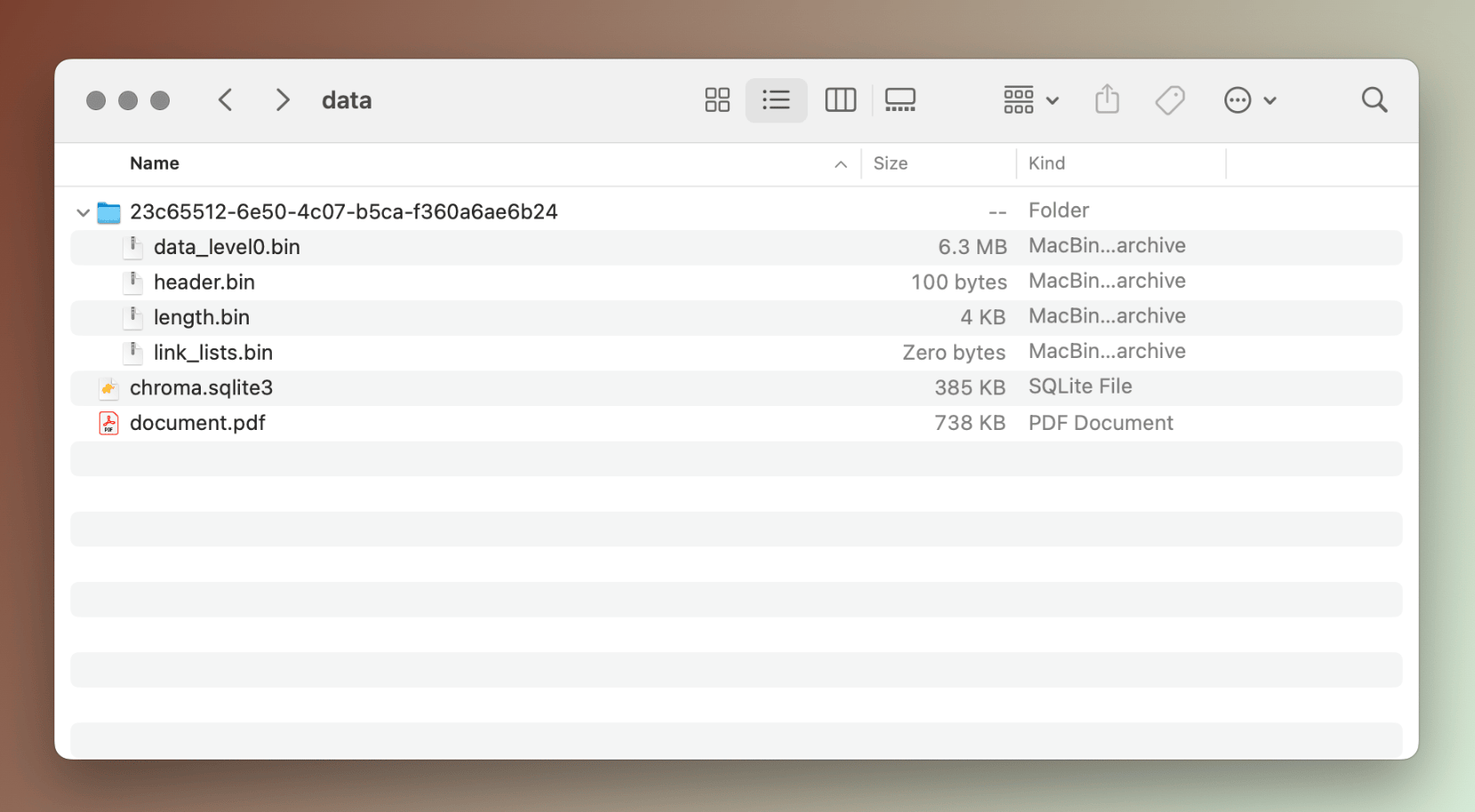
data directoryStep 4: Perform a similarity search locally
That was easy! Right? One of the benefits of Chroma is how efficient it is when handling large amounts of vector data. For this example, we're using a tiny PDF but in your real-world application, Chroma will have no problem performing these tasks on a lot more embeddings.
Let's perform a similarity search. This simply means that given a query, the database will find similar information from the stored vector embeddings. Let's see how this is done:
query = "What is this document about?"We can then use the similarity_search method:
docs = chroma_db.similarity_search(query)
Another useful method is similarity_search_with_score, which also returns the similarity score represented as a decimal between 0 and 1. (1 being a perfect match).
Step 5: Query the model
We have our query and similar documents in hand. Let's send them to the large language model that we defined earlier (in Step 3) as llm.
We're going to use LangChain's RetrievalQA chain and pass in a few parameters as shown below:
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=chroma_db.as_retriever())
response = chain(query)
What this does is create a chain of type stuff, use our defined llm, and our Chroma vector store as a retriever.
chain_type="stuff" lets LangChain take the list of matching documents from the retriever (Chroma DB in our case), insert everything all into a prompt, and pass it over to the llm.The response looks like this:
"This document discusses the concept of machine learning, artificial intelligence, and the idea of machines being able to think and learn. It explores the history and motivations behind the development of intelligent machines, as well as the capabilities and limitations of machines in terms of thinking. The document also mentions the potential impact of machines on employment and encourages readers to stay relevant by learning about artificial intelligence."
Success! 🎉 🎉 🎉
(Bonus) Common methods
Get a collection of documents
Here is how we can specify the collection_name and get all documents using the get() method:
chroma_db = Chroma(persist_directory="data", embedding_function=embeddings, collection_name="lc_chroma_demo")
collection = chroma_db.get()Example code showing how to use the .get() method in LangChain and Chroma
The get() method returns all the data, including all the ids, embeddings, metadata, and document data.
Update a document in the collection
We can also filter the results based on metadata that we assign to documents using the where parameter. To demonstrate this, I am going to add a tag to the first document called demo, update the database, and then find vectors tagged as demo:
# assigning custom tag metadata to first document
docs[0].metadata = {
"tag": "demo"
}
# updating the vector store
chroma_db.update_document(
document=docs[0],
document_id=collection['ids'][0]
)
# using the where parameter to filter the collection
collection = chroma_db.get(where={"tag" : "demo"})Example code to add custom metadata to a document in Chroma and LangChain
Delete a collection
The delete_collection() simply removes the collection from the vector store. Here's a quick example showing how you can do this:
chroma_db.delete_collection()Example code showing how to delete a collection in Chroma and LangChain
Final thoughts
Looking for the best vector database to use with LangChain? Consider Chroma since it is one of the most popular and stable options out there.
In this short tutorial, we saw how you would use Chroma and LangChain together to store and retrieve your vector embeddings and query a large language model.
Are you considering LangChain and/or Chroma? Let me know what you're working on in the comments below.
I hope you found the content useful. Please consider subscribing to this blog for free so you get notified whenever new posts are published and follow me on X for more updates!
Further readings
More from Getting Started with AI
- New to LangChain? Start here!
- What is the difference between fine-tuning and vector embeddings
- How to use the Milvus Vector Database with LangChain for vector embeddings
- From traditional SQL to vector databases in the age of artificial intelligence