How to scrape data from the Web using Python and BeautifulSoup
In this post, we'll cover the basics of web scraping, explore popular Python libraries, and work on a project to extract data from a website and save it in a CSV format on our local device.

Back in the early internet days, people used to manually copy and paste data from web sources into spreadsheets, or documents to perform analysis; this process is called manual web scraping. However, it became difficult to keep up with the expansion of available data on the web and the need to obtain it from different sources, so software was used to automate the process.
What is Web Scraping?
Web scraping is the process of extracting information from the web. Scraping is defined as something that has been obtained by removing it from a surface. In the context of "Web Scraping", the surface is the web, and we're removing the data (or HTML) from it.
Popular Web Scraping Libraries for Python
Libraries provide most of the code needed to perform a set of actions, wrapped neatly in a package that exposes a set of methods. Python is a popular programming language for Web Scraping due to the availability of solid and well-maintained libraries such as BeautifulSoup, and Scrapy.
We're going to cover BeautifulSoup in this article, but the logic applies to any other library, even if scraping is done through HTTP requests "manually".
Web Scraping Use Cases
Web scraping has been used since the dawn of the internet, across all industries. Some examples of use cases for web scraping include:
- Research and Insights: Web scraping is used to collect data from the latest developments in a specific topic such as news, or medical reports. It is also used to extract data from publicly available sources, such as stock markets, exchange rates, and others.
- Machine Learning Training Data: Similarly, data collected could be used to train machine learning models to output predictions.
Web Scraping Controversy
Web scraping raises a immediate questions of ethics and legality. You should ask yourself whether it is legal to scrape data from a website before attempting to do so. Many companies indicate if they allow scraping in their policies, however, even if it is not clearly stated you must always acquire consent from the data owner before attempting to scrape any data.
Just so you know, as soon as I typed "Is Web Scraping" into Google, it automatically appended the word legal and a question mark to my search query so it became "Is Web Scraping Legal?". This goes to show that this is a common question asked by many people. The short answer to that question is: It depends.
Keep in mind that some things to consider include (but are not limited to):
- Some data is protected by different laws (Including personal information, and other sensitive data)
- Some data owners consider scraping their data a violation of the terms and conditions they set
- Even if scraping itself is authorized, misusing the data could be a breach of some laws and policies
Notable Legal Cases
- Facebook v. Power Ventures: You can read more about the case here.
- Craigslist vs 3Tap: You can read more about the case here.
- HiQ v. LinkedIn: You can read more about the case here.
Overview of what we're building
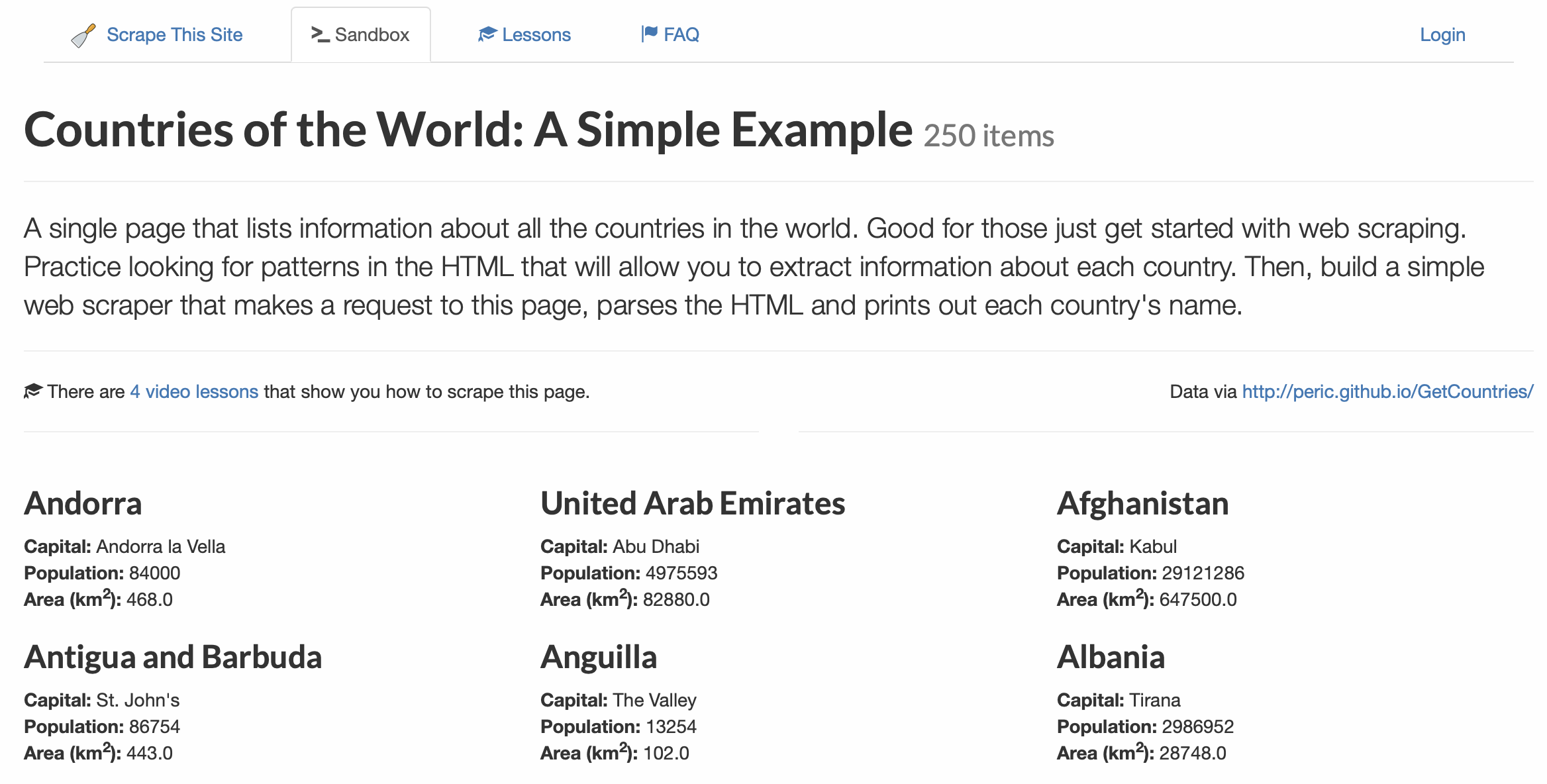
For this project, we're going to scrape country data from: https://www.scrapethissite.com. As you can tell from the domain name, the site's purpose is to help people understand web scraping.
Here's what they have to say about this:
This site is made for the purpose of teaching people the art of web scraping. Please feel free to write or use software in order to automatically pull, harvest, scrape, download or otherwise access any information on this site. - https://www.scrapethissite.com/faq/
We're going to collect the countries from this URL: https://www.scrapethissite.com/pages/simple/
On this page, you'll see three columns (depending on your screen size), listing country name, capital, population, and area (in km2) for all countries. The goal of this tutorial is to extract the country data, perform some filtering, then store everything in a CSV.
Prerequisites
We'll need to install a few things to get started:
- Python
- Jupyter Notebook (You can use your preferred IDE, such as VS Code)
- BeautifulSoup
- Pandas
1. Install Python
Let's start by installing Python from the official repository: https://www.python.org/downloads/
Download the package that is compatible with your operating system, and proceed with the installation. To make sure Python is correctly installed on your machine, type the following command into your terminal:
python --versionYou should get an output similar to this: Python 3.9.6
2. Install Jupyter Notebook
After making sure Python is installed on your machine (see above), we can proceed by using pip to install Jupyter Notebook.
In your terminal type the following:
pip install jupyter3. Install BeautifulSoup
Then we can install the BeautifulSoup library:
pip install beautifulsoup44. Install Pandas
Finally, type in the following to install pandas using pip:
pip install pandasGreat, we have everything we need to get started!
Building our Web Scraper
Before we start coding, let's dive deeper into the HTML structure to identify which tags we'll need to pull the data from, then, we can write the Python code that will perform the actual scraping.
Understanding the Tag Structure
Remember we're going to extract content from HTML tags. How do we know which tags contain our data? Simple, we have to look at the HTML source code of the page. Specifically, we're looking for tags holding these values:
- Country Name
- Country City
- Population
- Area (km2)
We can see the source code by opening the Web Inspector tool in our browser, to do so:
- Right-click on the first country "Andorra" (Or any other country name).
- As shown below, click on "Inspect Element" if you're using Safari. (For Chrome it's Inspect)

This will open the Web Inspector which shows the HTML code of the tag holding the selected value (Andorra in our case). Even though the inspector shows a lot of other technical information about the website, we'll only focus on identifying the tags that hold the values that we're looking to extract.
Looking at the Web Inspector window, we can notice a few things immediately:
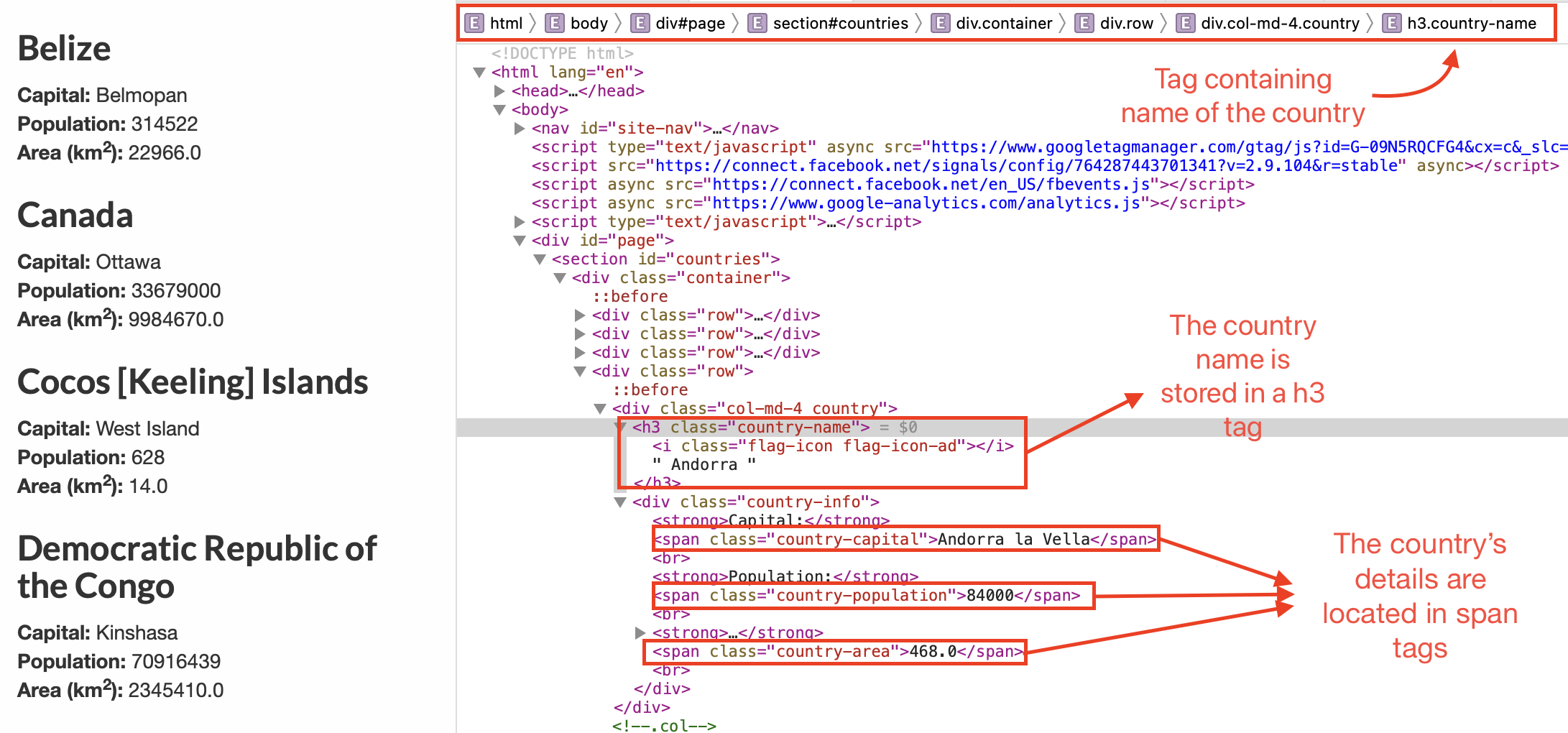
<h3 class="country-name">contains the Country Name<span class="country-capital">contains the Country's Capital<span class="country-population">contains the Country's Population<span class="country-area">contains the Country's Area
We can also see that the country details (capital, population, and area) are all nested in a <div> tag with a class value of country-info. Similarly, the tags with the classes country-name and, country-info are both nested in a parent <div> with class values of col-md-4 and country.
Putting Everything Together
Given the observation above, we can find everything nested in the <div class="col-md-4 country"> tag. This element is also repeated in every other country. This means we can:
- Grab all occurrences of this element
- Loop through each occurrence
- Extract the
textvalues of the target tags (name, capital, population, and area) - Put all the values in a list
- Convert that list to a pandas DataFrame
- Perform our DataFrame Analysis
- Save the data from the DataFrame as a CSV file
Launch Jupyter Notebook (Or your IDE of choice)
We're now ready to start coding!
Open your terminal window and cd to your project directory to launch a new instance of Jupyter Notebook. Type the following and hit return:
jupyter notebook
This command will automatically open your default browser, and redirect you to the Jupyter Notebook Home Page. You can select or create a notebook from this screen.
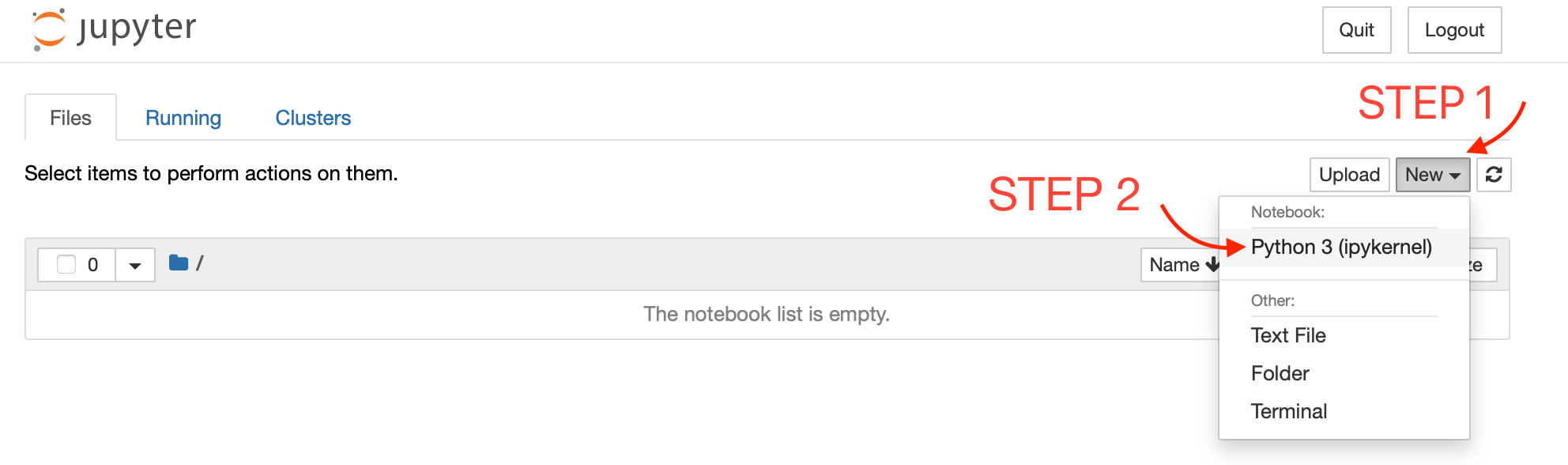
Create a new Notebook
Now let's create a new notebook by clicking on New -> Python3 as shown below:
Import required modules
First, we'll need to perform a GET request to fetch the HTML data from the site. We can do so with the help of the requests module. We'll import BeautifulSoup, and pandas so we can use them in a bit:
import requests
from bs4 import BeautifulSoup
import pandas as pdRetrieve content using GET method
We use the requests.get() method, to request the data from the url below:
url = "https://www.scrapethissite.com/pages/simple/"
response = requests.get(url)
# Store HTML content in html_content variable
html_content = response.contentParse HTML content using BeautifulSoup
Next, we instantiate a BeautifulSoup object by passing html_content which contains all of the HTML code from the url.
# Create a soup variable
# "html.parser" specifies the parser that matches the data type (HTML)
soup = BeautifulSoup(html_content, "html.parser")Retrieve all countries using a for loop
Let's find all the HTML <div> tags that have a class value of country using BeautifulSoup's .find_all() method. We'll then loop through each one of them and extract the values into a Python list data:
# Find all div tags with class country
countries = soup.find_all("div", class_="country")
# Instantiate list
data = []
# Loop through each country div
for country in countries:
# Extract the text from the h3 tag with class country-name
name = country.find("h3", class_="country-name").text.strip()
# Extract the text from the span tag with class country-capital
capital = country.find("span", class_="country-capital").text.strip()
# Extract the text from the span tag with class country-population
population = country.find("span", class_="country-population").text.strip()
# Extract the text from the span tag with class country-area
area = country.find("span", class_="country-area").text.strip()
# Append all text values to our data list
data.append([name, capital, population, area])The strip() method removes the leading and trailing whitespace characters from the .text value.
Convert to pandas DataFrame
Great, now we have all the countries stored neatly in our data list. We can quickly convert it to a pandas DataFrame:
# Create a pandas DataFrame from our data list
# Specify friendly column names using columns[] parameter
df = pd.DataFrame(data, columns=["Country Name", "Capital", "Population", "Area"])
# Convert the Area, and Population values to a numeric type
df["Area"] = pd.to_numeric(df["Area"])
df["Population"] = pd.to_numeric(df["Population"])Return the first five rows in DataFrame
df.head()| Country Name | Capital | Population | Area | |
|---|---|---|---|---|
| 0 | Andorra | Andorra la Vella | 84000 | 468.0 |
| 1 | United Arab Emirates | Abu Dhabi | 4975593 | 82880.0 |
| 2 | Afghanistan | Kabul | 29121286 | 647500.0 |
| 3 | Antigua and Barbuda | St. John's | 86754 | 443.0 |
| 4 | Anguilla | The Valley | 13254 | 102.0 |
Save DataFrame as CSV
Finally, we'll save our DataFrame into a CSV (short for Comma Separated Values) file:
# Save DataFrame as a CSV file
df.to_csv("country_data.csv", index=False)Conclusion
There you have it, a few lines of code and you can pull data from any website. Keep in mind that things in the real world are more complicated. In our project, the HTML structure was clear and very well-defined. Usually, you'll need to work with more complex things like paging and AJAX. You can check out the BeautifulSoup documentation and try to scrape data from the other example pages on scrapethissite.com.