AutoGen 0.4.8 Introduces Native Ollama Support: Run AI Agents Locally
AutoGen 0.4.8 just dropped with native Ollama integration using the new OllamaChatCompletionClient. No more workarounds and API costs.

So in my previous AutoGen tutorial, we set up Ollama using OpenAIChatCompletionClient and we passed a few parameters which really did not need! Luckily, a few days after the post was published the AutoGen team released version 0.4.8 which supports native Ollama using the new OllamaChatCompletionClient.
Here's the complete tutorial that gets you up to date in no time:
Why Ollama Integration Matters
If you've worked with AutoGen before, you know it's a fantastic framework for building multi-agent systems. But until now, you were mostly either limited to using cloud-based models through APIs like OpenAI or had to apply workarounds to the default OpenAIChatCompletionClient and pass some unecessary parameters just to add Ollama support.
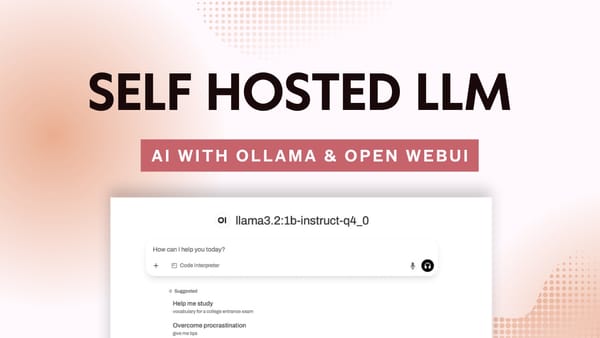
The latest AutoGen update, 0.4.8 support direct integration which means that now you can power your AI agent systems with locally-hosted models like Llama3, or any other model supported by Ollama.
Setting Up AutoGen with Ollama
Getting started with the new integration is refreshingly simple. First, make sure you have Ollama installed and running on your system with your models of choice.
Then install the new AutoGen extension:
pip install -U "autogen-ext[ollama]"
From there, you can create an Ollama client with just a few lines of code:
from autogen_ext.models.ollama import OllamaChatCompletionClient
# Create a client with your local Ollama model
ollama_client = OllamaChatCompletionClient(
model="llama3.2:latest"
)
# Pass it to your agent's model_client parameter
script_writer = AssistantAgent(
name="script_writer",
model_client=ollama_client, # <--
system_message='''
...
That's it! No API keys to manage, no workarounds, no tokens to count, and no data leaving your machine.
Structured Output from Local Models
One of the most impressive aspects of this integration is support for structured output. This means you can get formatted, parseable data from your local models. Setting this up is also super straight forward:
You'll need to define a new class and pass it to the response_format parameter when intializing the OllamaChatCompletionClient client. Here's what this looks like:
from pydantic import BaseModel
class ScriptOutput(BaseModel):
topic: str
takeaway: str
captions: list[str]
# Use it with Ollama
ollama_client = OllamaChatCompletionClient(
model="llama3.2:latest",
response_format=ScriptOutput,
)
...
script_writer = AssistantAgent(
name="script_writer",
model_client=ollama_client,
system_message='''
...
This gives you clean, structured data that's ready to use in your application logic, all while running on your local hardware.
I'm using the code from my previous post
Real-World Applications
This integration unlocks numerous practical applications:
-
Privacy-Sensitive Projects: Build applications that handle personal or confidential information without sending data to external APIs.
-
Cost-Effective Development: Develop and test agent systems without incurring API costs, especially important during the prototyping phase.
-
Offline Capabilities: Create applications that continue to function without internet connectivity.
-
Educational Settings: Use in classrooms or workshops where API access might be limited or costly.
-
Edge Deployment: Run agent systems on edge devices or in environments with limited connectivity.
Performance Considerations
It's worth noting that while local models provide these advantages, they typically require decent hardware, especially for larger models. The performance will depend on your system specifications and the specific models you're running through Ollama.
For many use cases, however, the tradeoff is well worth it. Models like Llama3 can run reasonably well on consumer hardware and provide impressive capabilities without the ongoing costs of API calls.
Looking Forward
This integration represents a significant step toward making advanced AI agent systems more accessible and practical for everyday development. As open-source models continue to improve and local inference becomes more efficient, the gap between cloud-based and locally-hosted solutions will likely continue to narrow.
The AutoGen team has shown they're listening to community needs with this update. By combining AutoGen's powerful agent framework with Ollama's simplified local model hosting, they've created a powerful combination that gives developers more freedom in how they build and deploy AI systems.
Whether you're concerned about costs, privacy, or simply want more control over your AI infrastructure, AutoGen 0.4.8's Ollama integration provides a compelling solution that's worth exploring.
To get started, check out the official AutoGen documentation and give the new Ollama integration a try in your next project.
- Official documentation: https://microsoft.github.io/autogen/stable/
- AutoGen 0.4 Complete Tutorial: https://www.gettingstarted.ai/autogen-multi-agent-workflow-tutorial/
- Setting up Ollama: https://youtu.be/iEQja9xS8pY