
Tutorial: Build Your Own RAG AI Agent with LlamaIndex
I built a custom AI agent that thinks and then acts. I didn't invent it though, these agents are known as ReAct Agents and I'll show you how to build one yourself using LlamaIndex in this tutorial.

Hi folks! Today, I'm super excited to show you how you can build a Python app that takes the contents of a web page and generates an optimization report based on the latest Google guidelines—all in under 10 seconds! This is perfect for bloggers and content creators who want to ensure their content meets Google's standards.
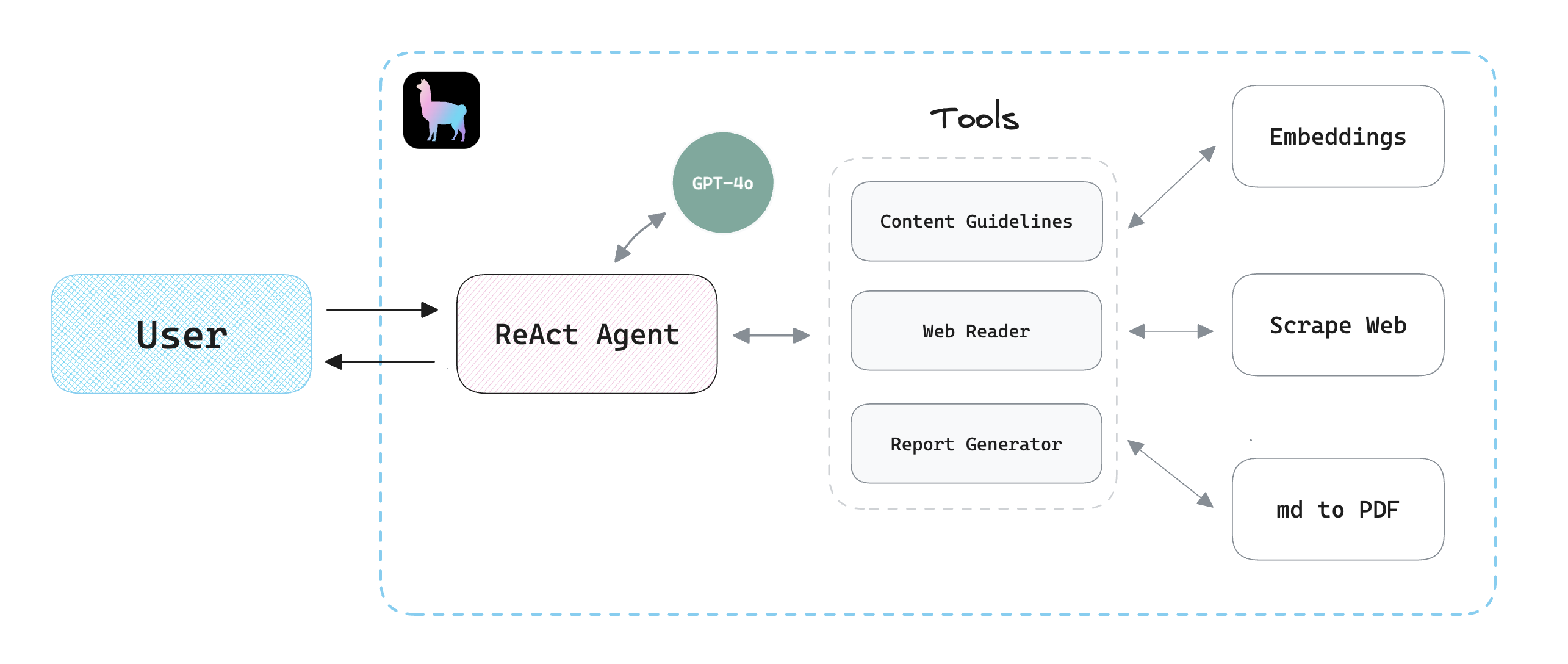
We'll use a LlamaIndex ReActAgent and three tools that will enable the AI agent to:
- Read the content of a blog post from a given URL.
- Process Google's content guidelines.
- Generate a PDF report based on the content and guidelines.
This is especially useful given the recent Google updates that have affected organic traffic for many bloggers. You may want to tweak this to suit your needs but in general, this should be a great starting point if you want to explore AI Agents.
Ok, let's dive in and build this!
Overview and scope
Here's what we'll cover:
- Architecture overview
- Setting up the environment
- Creating the tools
- Writing the main application
- Running the application
1. Architecture Overview
"ReAct" refers to Reason and Action. A ReAct agent understands and generates language, performs reasoning, and executes actions based on that understanding and since LlamaIndex provides a nice and easy-to-use interface to create ReAct agents and tools, we'll use it and OpenAI's latest model GPT-4o to build our app.
We'll create three simple tools:
- The
guidelinestool: Converts Google's guidelines to embeddings for reference. - The
web_readertool: Reads the contents of a given web page. - The
report_generatortool: Converts the model's response from markdown to a PDF report.
2. Setting up the environment
Let's start by creating a new project directory. Inside of it, we'll set up a new environment:
mkdir llamaindex-react-agent-demo
cd llamaindex-react-agent-demo
python3 -m venv venv
source venv/bin/activateNext, install the necessary packages:
pip install llama-index llama-index-llms-openai
pip install llama-index-readers-web llama-index-readers-file
pip install python-dotenv pypandocPDF we'll use a third-party tool called pandoc. You can follow the steps as outlined here to set it up on your machine.Finally, we'll create a .env file in the root directory and add our OpenAI API Key as follows:
OPENAI_API_KEY="PASTE_KEY_HERE"You can get your OpenAI API key from this URL.
3. Creating the Tools
Google Content Guidelines for Embeddings
Navigate to any page in your browser. In this tutorial, I'm using this page. Once you're there, convert it to a PDF. In general, you can do this by clicking on "File -> Export as PDF..." or something similar depending on your browser.
Save Google's content guidelines as a PDF and place it in a data folder. Then, create a tools folder and add a guidelines.py file:
import os
from llama_index.core import StorageContext, VectorStoreIndex, load_index_from_storage
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.readers.file import PDFReader
...After adding the required packages, we'll convert our PDF to embeddings and then create a VectorStoreIndex:
...
data = PDFReader().load_data(file=file_path)
index = VectorStoreIndex.from_documents(data, show_progress=False)
...Then, we return a QueryEngineTool which can be used by the agent:
...
query_engine = index.as_query_engine()
guidelines_engine = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="guidelines_engine",
description="This tool can retrieve content from the guidelines"
)
)Web Page Reader
Next, we'll write some code to give the agent the ability to read the contents of a webpage. Create a web_reader.py file in the tools folder:
# web_reader.py
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.readers.web import SimpleWebPageReader
...
url = "https://www.gettingstarted.ai/crewai-beginner-tutorial"
documents = SimpleWebPageReader(html_to_text=True).load_data([url])
index = SummaryIndex.from_documents(documents)
I'm using a SummaryIndex to process the documents, there are multiple other index types that you could decide to choose based on your data.
I'm also using SimpleWebPageReader to pull the contents of URL. Alternatively, you could implement your own function, but we'll just use this data loader to keep things simple.
Next, we'll build the QueryEngineTool object which will be provided to the agent just like we've done before:
query_engine = index.as_query_engine()
web_reader_engine = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="web_reader_engine",
description="This tool can retrieve content from a web page"
)
)Ok, cool. Now let's wrap up the tool and create our PDF report generator.
PDF Report Generator
For this one, we'll use a FunctionTool instead of a QueryEngineTool since the agent won't be querying an index but rather executing a Python function to generate the report.
Start by creating a report_generator.py file in the tools folder:
# report_generator.py
...
import tempfile
import pypandoc
from llama_index.core.tools import FunctionTool
def generate_report(md_text, output_file):
with tempfile.NamedTemporaryFile(delete=False, suffix=".md") as temp_md:
temp_md.write(md_text.encode("utf-8"))
temp_md_path = temp_md.name
try:
output = pypandoc.convert_file(temp_md_path, "pdf", outputfile=output_file)
return "Success"
finally:
os.remove(temp_md_path)
report_generator = FunctionTool.from_defaults(
fn=generate_report,
name="report_generator",
description="This tool can generate a PDF report from markdown text"
)I'm using pypandoc which is a Pandoc wrapper, so make sure that it's installed on your system if you're using the same code as above. For installation instructions, follow this guide.
4. Writing the Main Application
Awesome! All good. Now we'll put everything together in a main.py file:
# main.py
...
# llama_index
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import ReActAgent
# tools
from tools.guidelines import guidelines_engine
from tools.web_reader import web_reader_engine
from tools.report_generator import report_generator
llm = OpenAI(model="gpt-4o")
agent = ReActAgent.from_tools(
tools=[
guidelines_engine, # <---
web_reader_engine, # <---
report_generator # <---
],
llm=llm,
verbose=True
)
...As you can see, we start by importing the required packages and our tools, then we'll use the ReActAgent class to create our agent.
To create a simple chat loop, we'll write the following code and then run the app:
...
while True:
user_input = input("You: ")
if user_input.lower() == "quit":
break
response = agent.chat(user_input)
print("Agent: ", response)5. Running the Application
It's showtime! Let's run the application from the terminal:
python main.py
Feel free to use the following prompt, or customize it as you see fit:
"Based on the given web page, develop actionable tips including how to rewrite some of the content to optimize it in a way that is more aligned with the content guidelines. You must explain in a table why each suggestion improves content based on the guidelines, then create a report."
The agent will process the request, and call upon the tools as needed to generate a PDF report with actionable tips and explanations.
The whole process will look something like this:

You can clearly see how the agent is reasoning and thinking about the task at hand and then devising a plan on how to execute it. With the assistance of the tools that we've created, we can give it extra capabilities, like generating a PDF report.
Here's the final PDF report:

Conclusion
And that's it! You've built a smart AI agent that can optimize your blog content based on Google's guidelines. This tool can save you a lot of time and ensure your content is always up to standard.
Make sure to create a free account to grab the full source code below. Also, let's connect on X and subscribe to my YouTube channel for more! I'd love to know if you have any questions or feedback.
See you soon!