
A practical guide to automating your ETL pipeline using Apache Airflow
In this article, we will undertake a simple project using Apache Airflow, acquire knowledge and put into practice the ETL process.

Back in 2014, the team at Airbnb developed an internal solution to manage the company's increasingly complex workflows. They called it Airflow. It is an orchestration tool that makes it easy to schedule, and monitor a collection of related tasks.
What is a Workflow
A workflow is defined as a sequence of tasks that processes a set of data through a specific path from start to finish. It is meant to automate a sequence of tasks that will save us a lot of time. A group of individual-related tasks, like reading and replying to emails, or reviewing bank statements and entering expenses into an Excel sheet, can be defined as a workflow.
Workflow Use Cases
Here are a few use cases that can make use of workflows in general:
- Business intelligence
- Logs processing and analytics
- Machine learning prediction model
Our main focus will be on the practical implementation of a Machine Learning prediction model. We will explore how to create a workflow using Airflow, which will help us to gather, process, and store data efficiently.
Defining the ETL Workflow
For this project, we're going to assume that we're building a machine learning model that will predict a house price based on historical data. To keep this simple, we'll use a JSON file as the primary data source, but in the real world you'll be dealing with more complex data sources, such as:
- External databases
- Internal databases
- Third-party APIs (JSON, XML, Etc.)
Extracting Data
Ok, so we'll start by collecting the data from the JSON file using Python. We'll perform open() and json.load() methods to read and return the data.
Transforming Data
The next step is to work with the JSON data and convert it to a pandas DataFrame and save it locally as a CSV file. The DataFrame allows us to easily modify the data so that it can be used for analysis and model training later.
Loading Data
Finally, after we transform our data, we'll use scikit-learn (an ML library for Python) split our dataset into training and testing data so that it can be used to teach our model to make predictions.
Combining all titles from the steps above, we get Extract, Transform, and Load also known as ETL. It is a three-step workflow essentially achieving the below:
- Task 1: Extracting the Data
- Task 2: Transforming the Data
- Task 3: Loading the Data
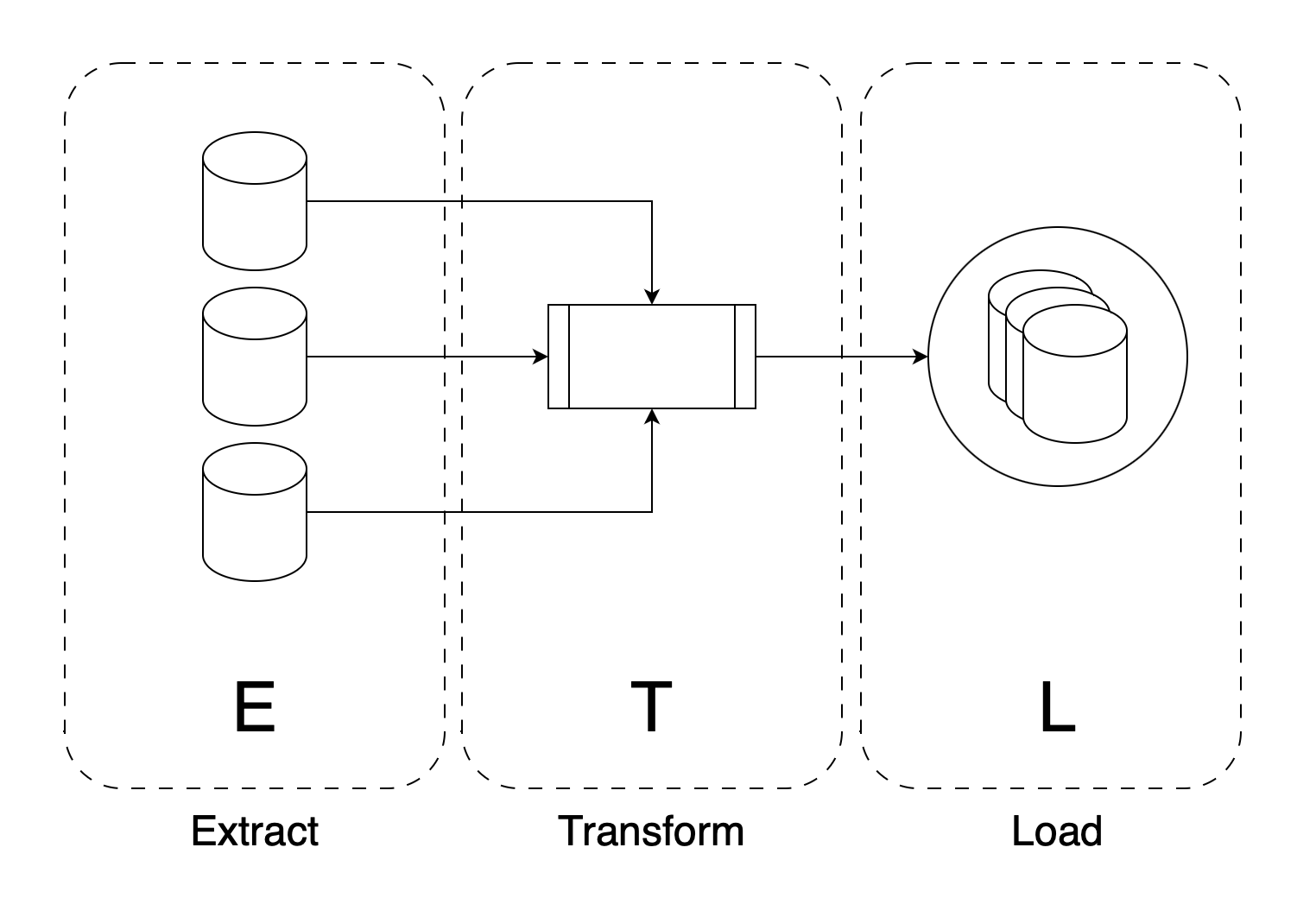
Apache Airflow
You'll often hear that Airflow is a good tool for ETL. While this is true, Airflow is a great tool for running any type of workflow given its simple user interface and its extensibility using operators (we'll get to that in a bit).
Introduction to DAGs
A DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run. - https://airflow.apache.org
Basically, a DAG is a collection of Tasks. The DAG contains specific instructions that dictate how its embedded tasks run, as well as, their order of execution. It's important to mention that the term Directed Acyclic Graph refers to a structure that does not contain any cycles, meaning the relationships between tasks cannot repeat or loop back on themselves, ensuring a one-way flow of task execution.
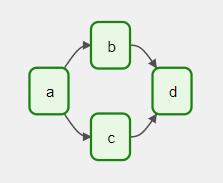
When a DAG is executed, it is instantiated into a DAG Run. DAGs can be executed either manually, or automatically if the DAGs' definition includes a schedule.
Operators -> Tasks
Think of the operator as a template that can be used to create a new Task. It provides the necessary elements to perform the task but can be customized and tweaked as necessary.
Airflow has an extensive list of built-in operators that can be used to perform many tasks. Some of the most popular are:
EmailOperator: Sends an emailBashOperator: Executes a bash commandPythonOperator: Calls a Python function
There are community operators as well, so many of them, in fact, you can find an operator for almost anything you might need. If you don't you could simply write your own.
Tasks -> Task Instance
Tasks will run as part of a DAG execution, which instantiates as a DAG Run. Similarly, a task under that DAG, will be instantiated as a Task Instance. The task instance keeps track of the status (or state) of the task. In Airflow, there are multiple states that are set by each component. Take a look at the below diagram:
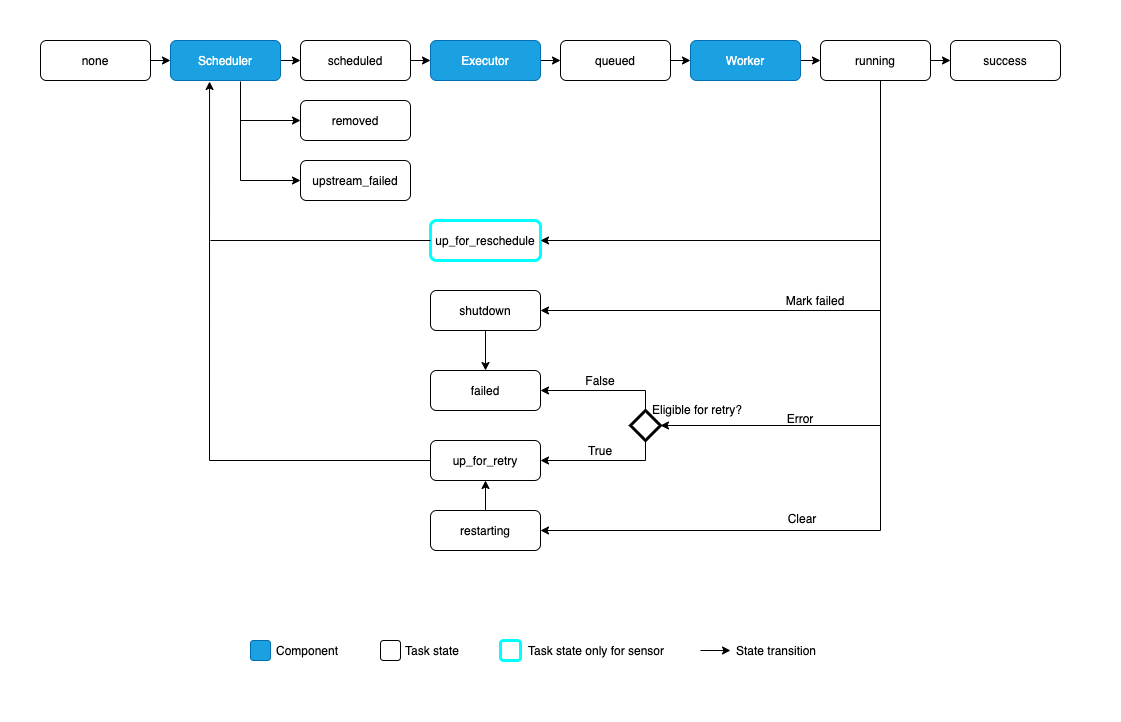
This basically shows the states in a lifecycle of a task instance.
Apache Airflow for ETL
Our goal is to have a DAG that looks like this:

This graph shows three connected individual tasks:
- extract_data_from_api: This will be our first task that will read and return the contents of a local
JSONfile. - transform_data_and_store: This will use the
JSONdata to make some transformations to it usingpandas, and then save it asCSV. - train_linear_regression_model: The last task will read from the
CSVdata, split it into training and testing data, and then fit a linear regression model.
Task 1: Extracting the Data from a JSON file
For our first task, we're going to use the open method in Python to read from a local file data.json.
GET request to an API, or a SELECT query on a database somewhere.Here's our first Task:
# Task 1: Extract data from the local JSON file
def extract_data_from_json():
json_file_path = '/path/to/data.json' # Replace with your path
with open(json_file_path, 'r') as file:
data = json.load(file)
return data
# Define the tasks
task1 = PythonOperator(
task_id='extract_data_from_json',
python_callable=extract_data_from_json,
dag=dag
)Let's break it down:
- In our function
extract_data_from_json()we're simply loading theJSONfile from its local pathpath/to/data.jsonand returning itsJSONformatted data. task1is our actual Apache Airflow task. It is using thePythonOperatorOperator since it will execute a Python methodextract_data_from_json()as indicated in thepython_callableparameter.task_idis a unique identifier that must be unique across all other tasks in this particular DAG.dagis a reference to the DAG that will contain this task, in our case, it's calleddagand we'll get to its implementation in a bit.
Task 2: Transforming the data and storing it as CSV
# Task 2: Transform the data with pandas and store it as CSV
def transform_data_and_store(**context):
data = context['ti'].xcom_pull(task_ids='extract_data_from_json')
df = pd.DataFrame(data)
df = df.rename(columns={'Price': 'price', 'SquareFootage': 'sqft'})
df.to_csv('output.csv', index=False)
task2 = PythonOperator(
task_id='transform_data_and_store',
python_callable=transform_data_and_store,
provide_context=True,
dag=dag
)Let's break it down:
- In our function
transform_data_and_store(**context)we're expecting a context variable (which represents the data fromtask1) which we're converting as aDataFrameto transform the data. (We're just changing the title of the columns from Price to "price", and SquareFootage to "sqft"). Finally, we're saving the modified data to a local file in CSV format asoutput.csv. task2is our actual Apache Airflow task. It is using thePythonOperatorOperator since it will execute a Python methodtransform_data_and_store()as indicated in thepython_callableparameter.task_idis a unique identifier that must be unique across all other tasks in this particular DAG.provide_contextis set toTrueso that Airflow knows to pass the context fromtask1totask2so thattask2has access to thedatafromtask1.dagis a reference to the DAG that will contain this task, in our case, it's calleddagand we'll get to its implementation in a bit.
Task 3: Load the data into a machine learning model
# Task 3: Train linear regression model with scikit-learn
def train_linear_regression_model():
data = pd.read_csv('output.csv')
X = data['sqft'].values.reshape(-1, 1)
y = data['price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
task3 = PythonOperator(
task_id='train_linear_regression_model',
python_callable=train_linear_regression_model,
dag=dag
)Let's break it down:
- In our function
train_linear_regression_model()we're loading the previously savedoutput.csvfile, defining our X, and Y variables, splitting the data into training and testing sets, and fitting a linear regression model. task3is our actual Apache Airflow task. It is using thePythonOperatorOperator since it will execute a Python methodtrain_linear_regression_model()as indicated in thepython_callableparameter.task_idis a unique identifier that must be unique to all other tasks in this particular DAG.dagis a reference to the DAG that will contain this task, in our case, it's calleddagand we'll get to its implementation in a bit.
Instantiating our DAG
# Define the DAG
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 5, 29),
}
dag = DAG('ml_training', default_args=default_args, schedule_interval=None)Let's break it down
We define our DAG as a variable called dag. The DAG constructor expects at least these three required parameters:
dag_id: This is a unique identifier for the DAG, in our caseml_training.default_args: A dictionary containing the default arguments for the DAG. We defined our args indefault_argswhich is then passed as the second parameter.schedule_interval: Either a time object or a cron expression that describes an interval when the DAG should be triggered. We putNonewhich basically tells the DAG that we'll run it manually.
Defining Task Order
Finally, we define the order of our tasks. Since we want task1 to run first, then task2, and finally task3. We can do the following:
# Define the task direction (task dependency)
task1 >> task2 >> task3The >> operator in Airflow defines the direction of tasks within a DAG, so that a DAG Run ensures the tasks are executed in the proper order.
Performing a DAG Run
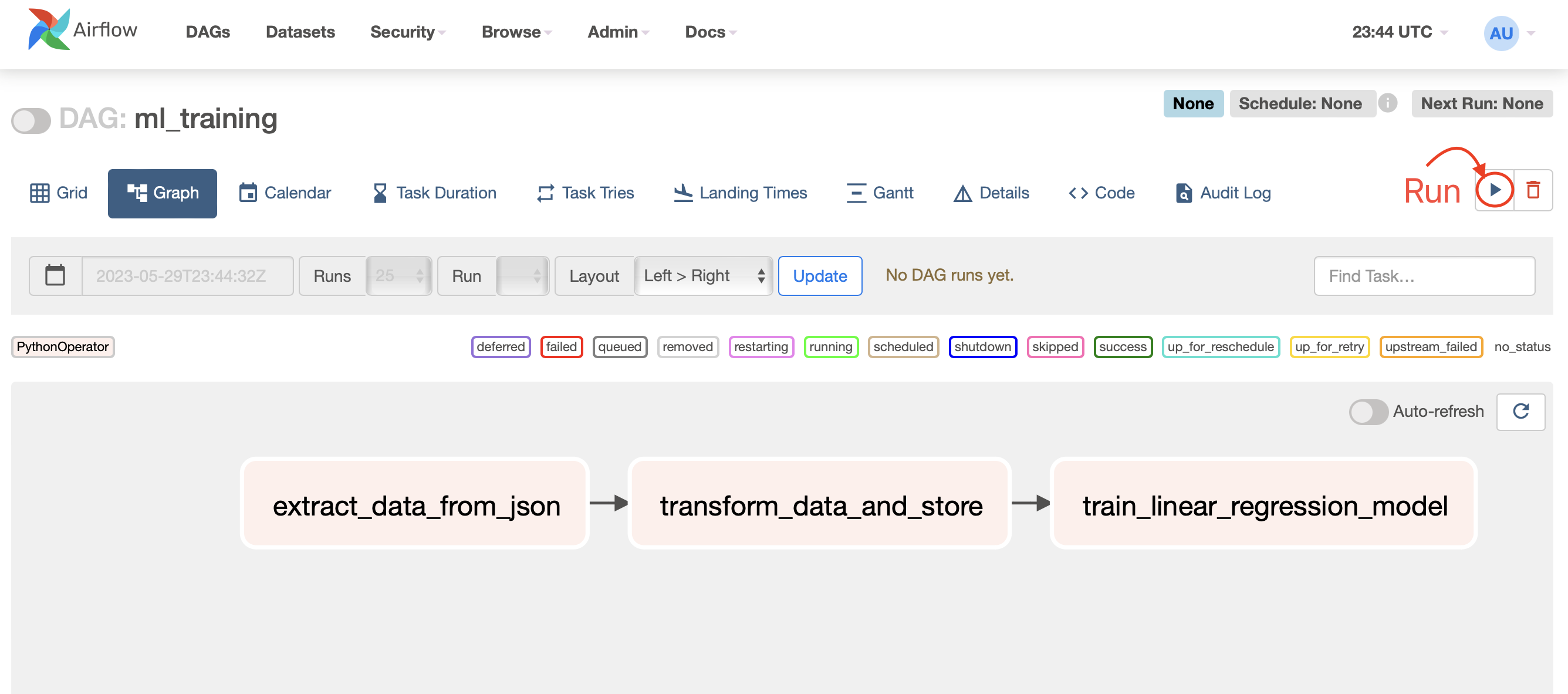
If all is well, our graph will change to look like this:

Conclusion
This post was a simple introduction to the concept of ETL, and how it can be applied using Apache Airflow. The tasks that will apply in your case will probably be completely different from what you saw here but the same logic applies. Having read this post, you will have everything you need to get started with Apache Airflow and explore its capabilities to fit your use case.
Thank you for reading!
JSON file used for this project can be found here.