How to extract metadata from PDF and convert to JSON using LangChain and GPT
A task like converting a PDF to JSON used to be complicated but can now be done in a few minutes. In this post, we're going to see how LangChain and GPT can help us achieve this.

Hi folks! Let me start by saying thank you for being here and a reminder to subscribe if you're not a member already.
Today's post is about a recent task that I was working on, specifically extracting the contents of a PDF file and converting it to JSON.
So, if you're wondering how to do this, you've come to the right place! 💡
Prefer to learn by watching?
If that's the case, here's a video version of this tutorial:
Metadata extraction using LLMs
After some research, I decided that the best way to approach this is to use a large language model to extract the fields that I needed.
The fastest way to do this? LangChain + OpenAI's GPT.
Extract metadata from PDF
Let's assume that the PDF we're working with is an excerpt from one of the posts on this blog and we want to extract key metadata about that post, specifically:
- Title
- Author
- Summary
- Keywords used
Thankfully, LangChain helps us achieve this in two ways:
- Output Parsers
- Extraction using OpenAI Functions

Depending on your requirements, you have to weigh the pros and cons of each but regardless of which approach you go for, the data ingestion phase is the same.
Data ingestion using LangChain
Briefly, data ingestion takes care of loading the contents of the PDF and structuring it in a usable way (as you'll see below).
I decided to create a single method that takes in a file path, loads the data, and returns it. Using LangChain's PDF data loader, it looks like this:
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFLoader
...
llm = ChatOpenAI()
def load_pdf():
loader = PyPDFLoader("demo.pdf")
pages = loader.load()
return pages load_pdf() using PyPDFLoader
The function load_pdf() uses PyPDFLoader to convert the contents of the PDF file into pages, a collection of LangChain Documents that we can later use as context for metadata extraction.
Before I forget, here's the PDF that I'm using for this example:
Method 1: LangChain Output Parsers
LangChain's Output Parsers convert LLM output to a specified format, like JSON.
Here's how we can use the Output Parsers to extract and parse data from our PDF file.
Step 1: Prepare your Pydantic object
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
class Document(BaseModel):
title: str = Field(description="Post title")
author: str = Field(description="Post author")
summary: str = Field(description="Post summary")
keywords: List[str] = Field(description="Keywords used")langchain_core.pydantic_v1 to import BaseModel and other Pydantic classes for use with LangChain. Importing directly from pydantic may cause parsing issues.Step 2: Use JsonOutputParser and PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
...
parser = JsonOutputParser(pydantic_object=Document)The pydantic_object is an optional field. You could also create a parser by just referencing JsonOutputParser:
parser = JsonOutputParser()Keep in mind that this will not supplement the LLM with any schematic information, which means that the model will not have a clearly defined JSON structure to work with and it may generate fields you may or may not need.
Next, we create our PromptTemplate:
from langchain_core.prompts import PromptTemplate
...
prompt = PromptTemplate(
template="Extract the information as specified.\n{format_instructions}\n{context}\n",
input_variables=["context"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)Step 3: Create and invoke the chain
I'm using LangChain Expression Language (or LCEL) below. You can read more about it on the official blog.
pages = load_pdf()
chain = prompt | llm | parser
response = chain.invoke({
"context": pages
})And that's it! If we run and print the response from the chain, we'll see the following output:
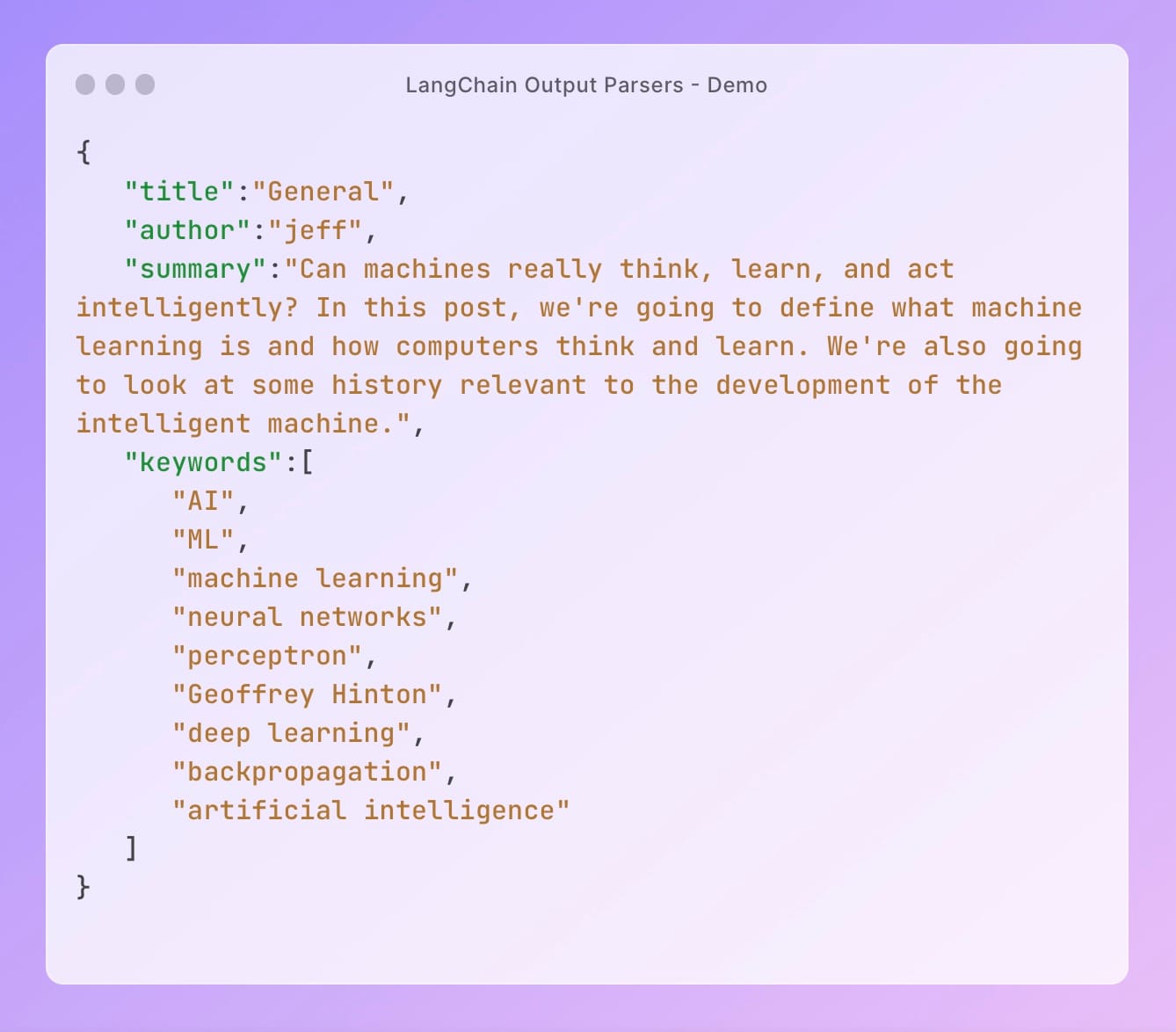
Beautiful, eh? Just like magic. 🪄

Method 2: Using OpenAI Functions
Since GPT supports function calling, we can define a schema of the properties we want to extract from the model and LangChain will take care of the rest. 👏
Internally, LangChain calls the _get_extraction_function method which essentially prompts the LLM to extract the data exactly as specified in the schema.
Here's an excerpt from the LangChain source code:
"""
Extract and save the relevant entities mentioned \
in the following passage together with their properties.
Only extract the properties mentioned in the 'information_extraction' function.
If a property is not present and is not required in the function parameters, do not include it in the output.
Passage:
{input}
"""Excerpt from LangChain source code extraction.py
Okay, so here's what we're going to do:
- Step 1: Define a schema
- Step 2: Use the
create_extraction_chainmethod - Step 3: Run the chain
Step 1: Define the schema
schema = {
"properties": {
"title": {"type": "string"},
"summary": {"type": "string"},
"author": {"type": "string"},
"keywords": {"type": "array", "items": {"type": "string"}},
},
"required": ["title", "summary", "author", "keywords"]
}Document from above, but we'll need to use the create_extraction_chain_pydantic method instead.Step 2: Create the extraction chain
from langchain.chains import create_extraction_chain
...
chain = create_extraction_chain(schema, llm)Using the LangChain extraction chain
If you'd like to use the Pydantic object (from Method 1 used with Output Parsers) instead of a schema, you can build the chain as follows:
from langchain.chains import create_extraction_chain_pydantic
...
chain = create_extraction_chain_pydantic(Document, llm)Provide the Document object as first parameter.
JSON since the chain returns a Pydantic object.Almost there, we just need to run the chain and print the response.
Step 3: Run the chain
To run the chain, we need to provide it with a list of pages (the contents of the PDF in our case), we'll use our load_pdf() function and then run the chain, as shown here:
pages = load_pdf()
response = chain.run(pages)
print(response)Running the extraction chain
Here's what the response looks like:👇

Voila! Magic. Notice the difference between the extraction chain and the output parsers?
What is the difference between LangChain Output Parsers and Extraction chains?
While both methods are used for the same purpose, there are a few notable differences.
The Output Parsers extract what is specifically defined in the schema while the extraction chain could infer values beyond the provided schema.
Another important differentiator is that the Output Parsers are not specific to any model, while the extraction chain makes use of LLM Functions which are not supported by all models.
Conclusion and thoughts
It's 2024, and some things that used to take several hours can now be done in a few minutes thanks to the advancements of large language models and the frameworks around them.
The code you see above is a modified version of what I wrote for a real-world application but you can easily modify it yourself to achieve the same output for other data types using LangChain's built-in data loaders and output parsers.
I'd love to know if you found this post helpful and make sure to drop your questions in the comments below, I try my best to respond as fast as possible!
Happy coding 🥂
Further readings
More from Getting Started with AI
- OpenAI Function Calling: An example using the Assistants API Functions tool
- Just getting started with LangChain? Here's everything you need to know
- How to use LangChain output parsers to structure large language model responses