The beginner's guide to start using the new Gemini Pro models in Google AI Studio
You've heard about the GPT killer from Google: Gemini. Read this guide to see how you can take Google's new AI model for a spin.

What is Gemini?
Last week, Google announced Gemini its latest and most capable AI model that aims to take OpenAI's GPT head-on. Gemini is built with multimodality in mind, this means that it is capable of understanding text, images, videos, audio, and code.
There are three versions of Gemini. Nano and Pro are available now, and Ultra is coming early next year. Gemini replaces PaLM 2 as the generative AI model powering Bard.
What is Google AI Studio?
Google AI Studio is a free web-based tool that provides access to Google's AI generative models including Gemini. It lets you easily test Google's AI models and experiment with different scenarios and use cases.
After you're done experimenting, Google AI Studio lets you export the code in many popular programming languages, including Python, JavaScript, and others.
What is Google Vertex AI?
Vertex AI provides the Gemini API which gives you access to the Gemini Pro and Pro Vision models. Vertex AI is part of the Google Cloud Platform and unlike the AI Studio it offers a full solution to develop, train, deploy, and monitor ML models.
To keep this post simple, we're only going to go over the Google AI Studio.
Here's what we're going to do
Okay, great! We've covered important information so far. We're now going to try the AI Studio and write a simple multimodal prompt to ask the Gemini Pro Vision model whether a certain coffee drink is good for someone on a Vegan diet.
Then we'll quickly go over how to generate the necessary code for this prompt and see how it could be added to our application.

How to use Google AI Studio
Let's go through the user interface of Google AI Studio first and see how we can start testing and generating code for our app in no time.
Get access to Google AI Studio
First things first! Head over to the Google AI site and sign in with your Google account.
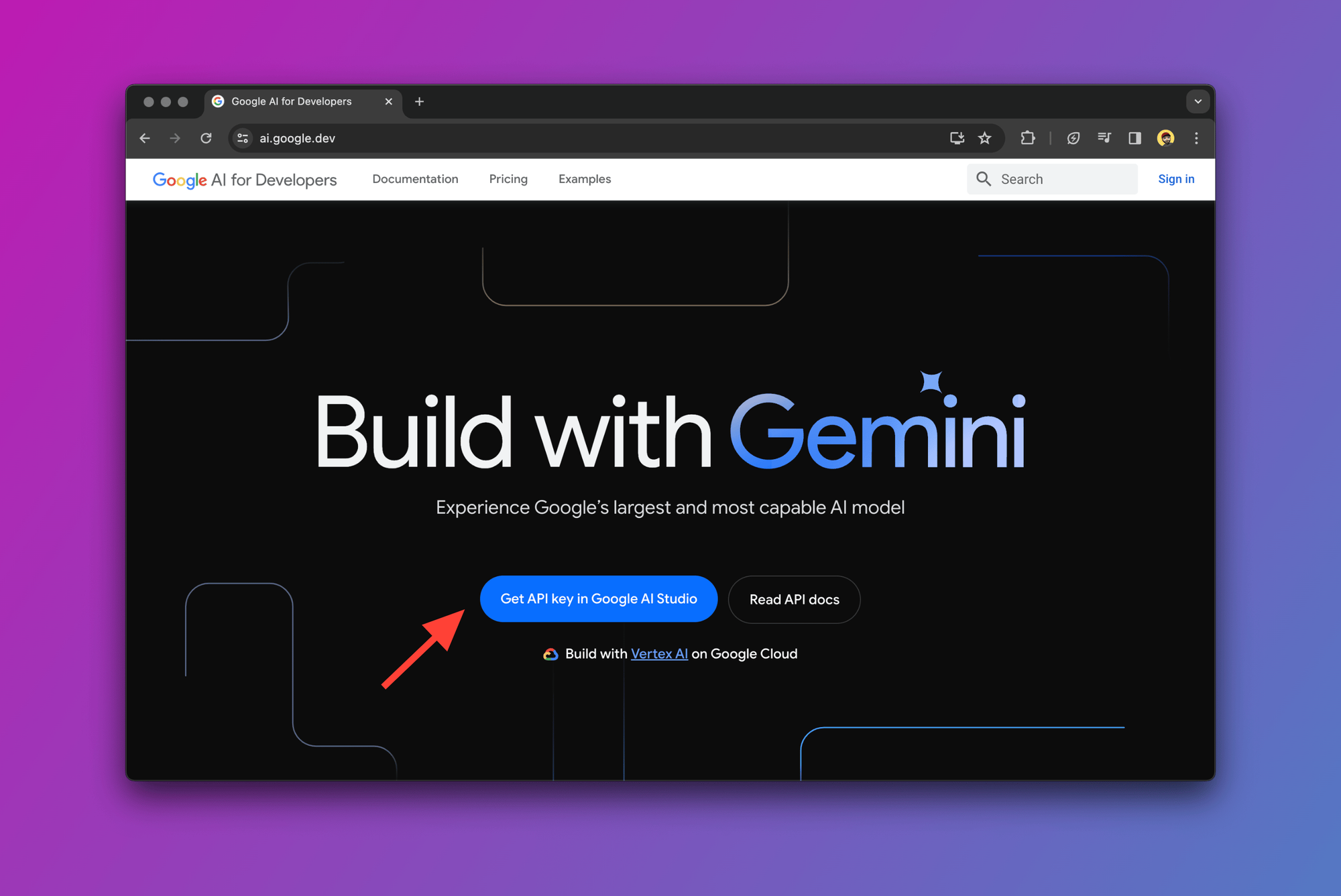
After you click on "Get API key in Google AI Studio", you'll be redirected to the main page where we're going to create our first prompt.
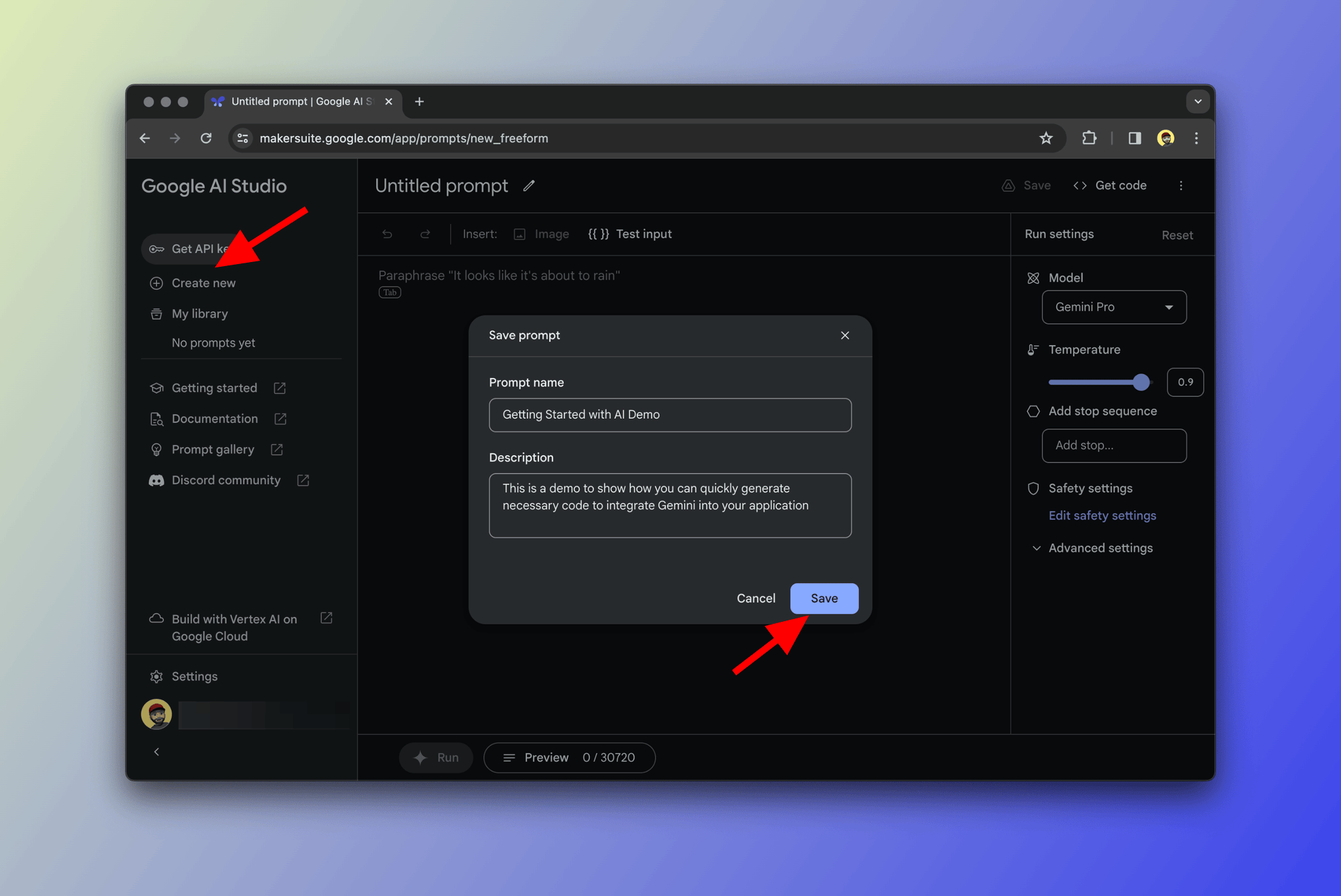
Create a new prompt
After you click on "Create New" as shown below, you'll have a few options to choose from. Go ahead and pick "Freeform prompt". It's just an interactive text area where you can write prompts and generate responses from the model.
Gemini Pro vs. Gemini Pro Vision
Currently, the following models are supported within the Vertex AI Gemini API and the Google AI Studio:
- Gemini Pro: Used for natural language tasks, multi-turn text, and code generation.
- Gemini Pro Vision: Supports multimodal prompts. This means that prompts can include text, images, and video.
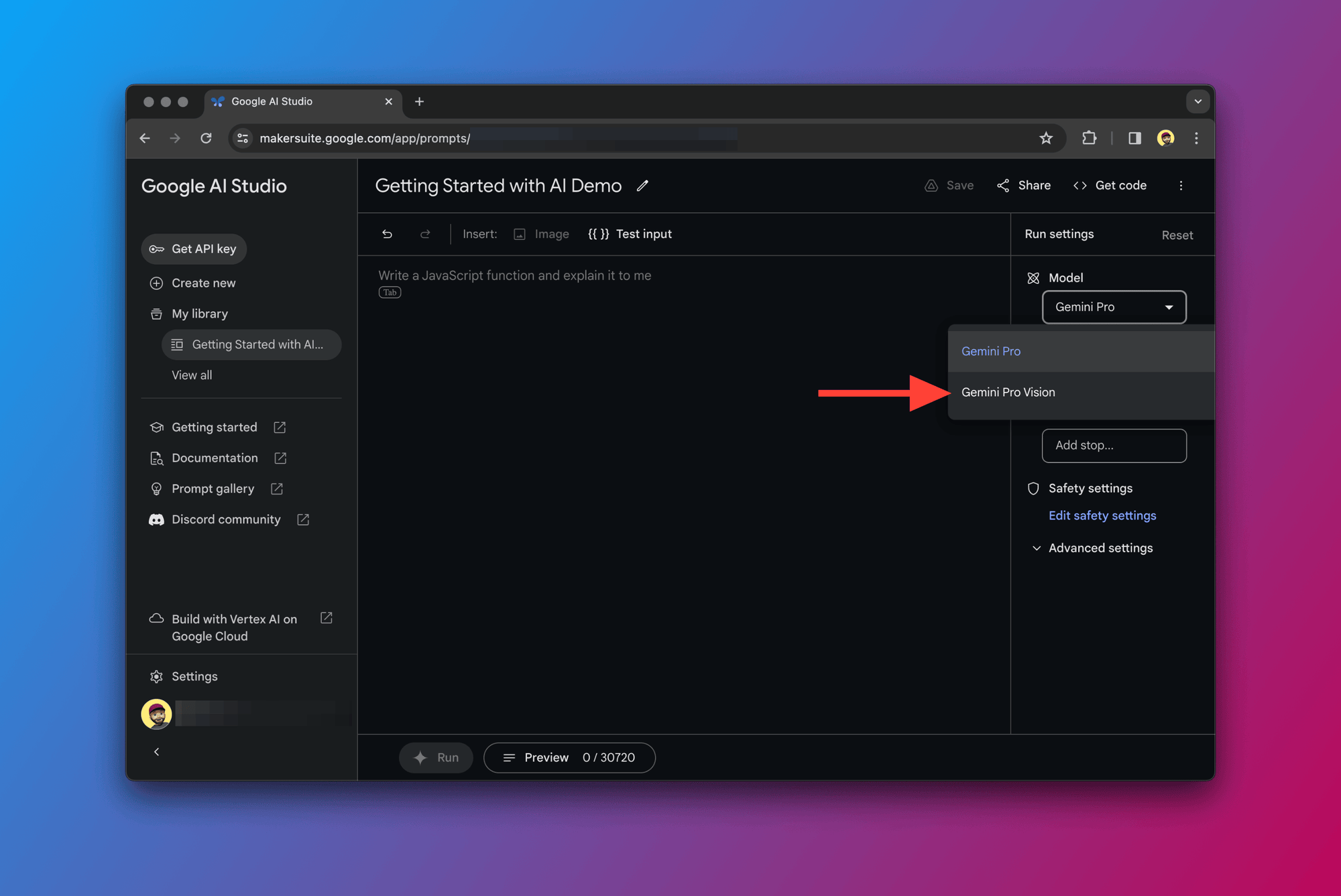
Choose Gemini Pro Vision for multimodal prompting
Okay, for this example we're going to switch over to the Gemini Pro Vision model and write a multimodal prompt made up of text and the image below:

Just click on the "Model" drop-down as shown below and choose "Gemini Pro Vision".
Easy. Right? I am now going to write this simple prompt in the text area: "Is this suitable for someone on a Vegan diet?" and attach the image of the latte drink above.
Gemini will process the text prompt then identify what is in the image then respond to the prompt based on the given information.
Let's do it:
- Type in our prompt
- Insert our image
- Click on "Run" (Alternatively, you could use
CMD+return)
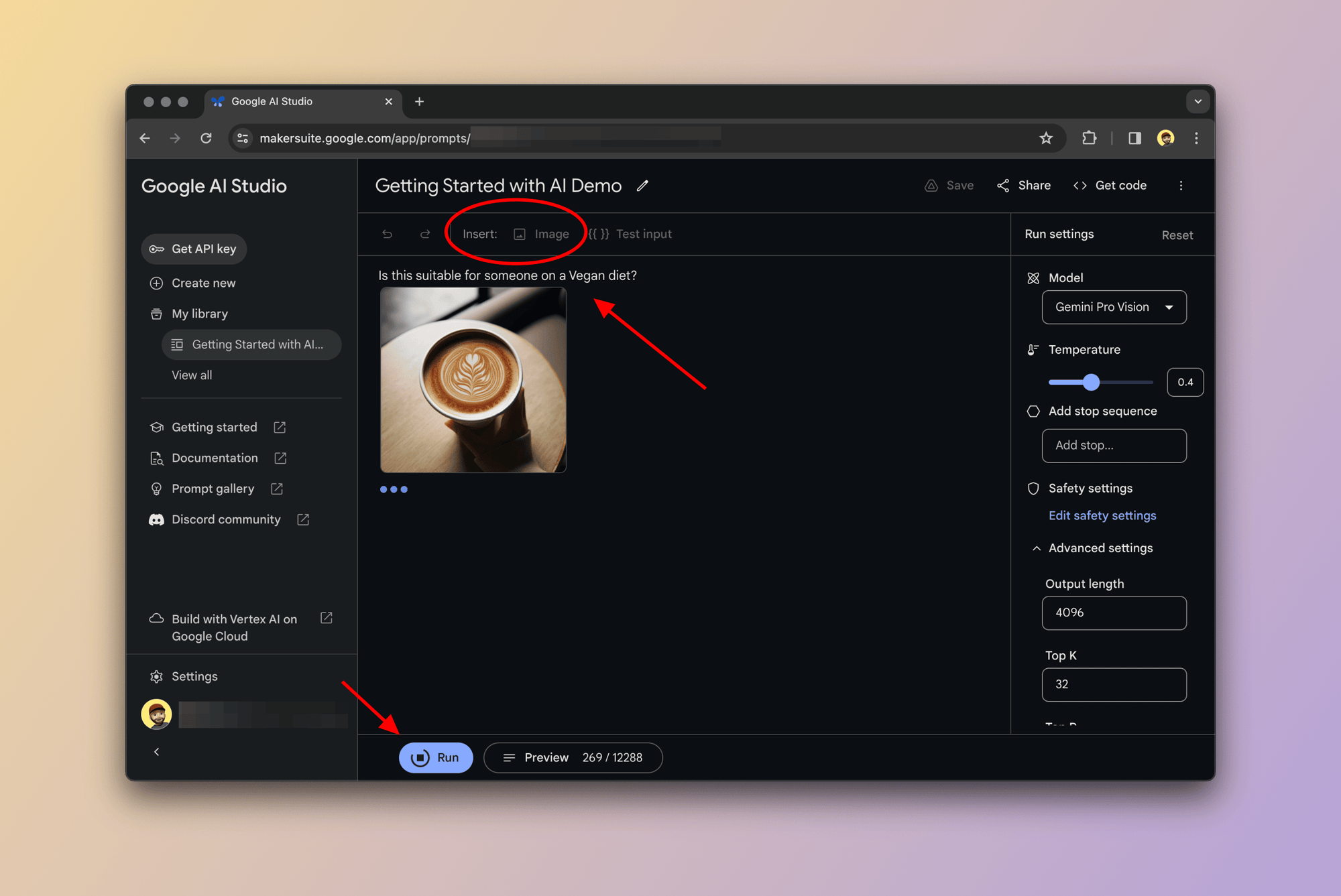
In this case, Gemini Pro Vision took a second and responded with the below:
"Vegans do not consume any animal products so will not drink cow's milk. It is possible to order a plant-based milk alternative such as oat milk, soy milk or almond milk."
That's a good answer to be honest. It determined that the drink contains milk but assumed that it was cow's milk, which is a good assumption since it is the most popular.
I asked GPT-4 the same thing and this was the answer:
"The image you've provided shows a cup of coffee with what appears to be latte art on the surface of the beverage. If the beverage is made with cow's milk, it would not be suitable for someone on a vegan diet, as vegans do not consume dairy products.
However, if the milk used to create the latte art is a plant-based alternative such as soy milk, almond milk, oat milk, or any other dairy-free milk, then it would be suitable for a vegan diet."
GPT-4 did slightly better in my opinion since it did not assume that the drink contains cows' milk by default.
Export the code to your app
When you're done experimenting with different prompts and scenarios, you can easily grab the code and paste it into your application.
To do so, click on the "Get Code" button as shown below:
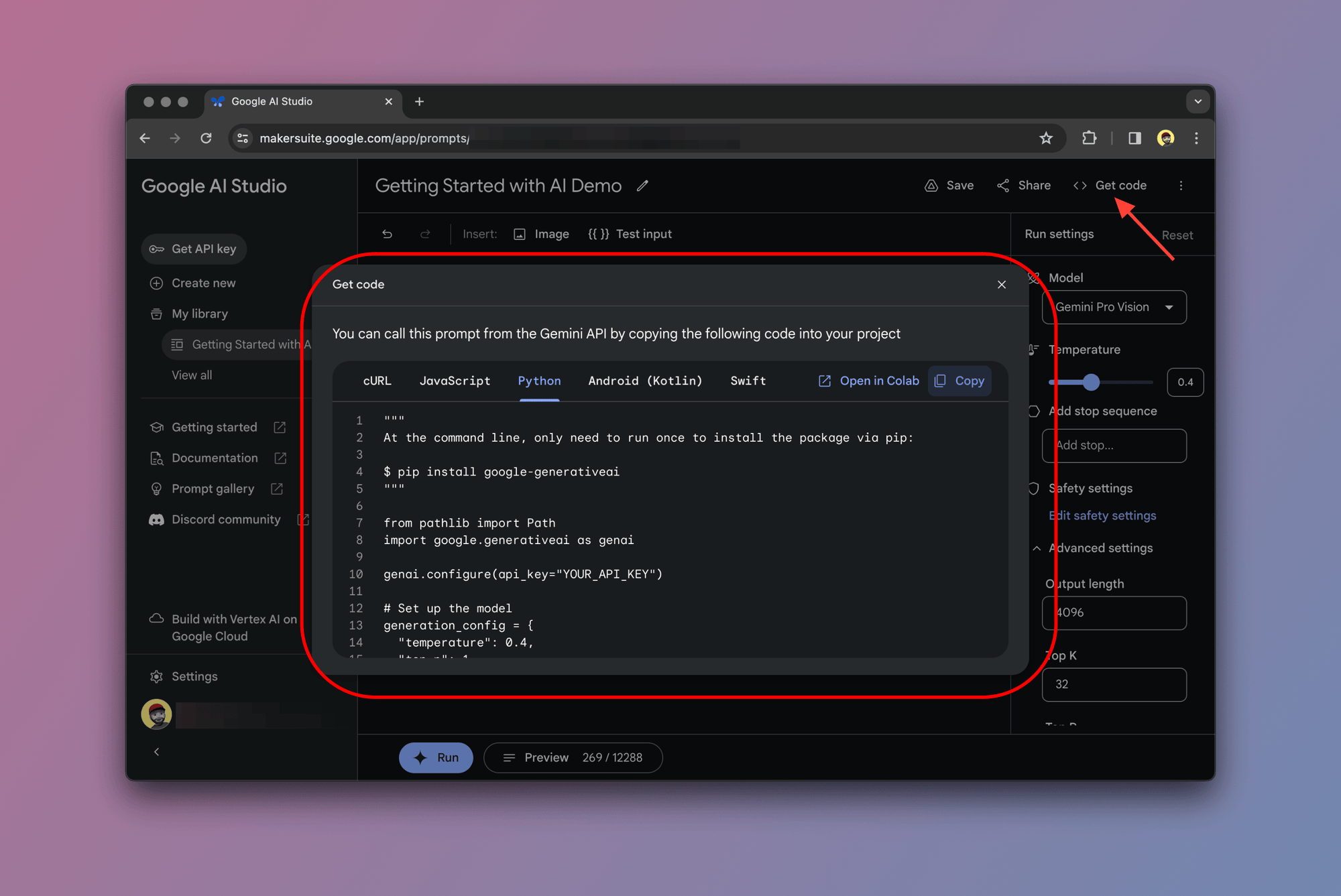
Google AI Studio lets you choose from a range of supported programming languages including Python and JavaScript.
Here's the code that the Google AI Studio generated for our prompt:
"""
At the command line, only need to run once to install the package via pip:
$ pip install google-generativeai
"""
from pathlib import Path
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Set up the model
generation_config = {
"temperature": 0.4,
"top_p": 1,
"top_k": 32,
"max_output_tokens": 4096,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro-vision",
generation_config=generation_config,
safety_settings=safety_settings)
# Validate that an image is present
if not (img := Path("image0.png")).exists():
raise FileNotFoundError(f"Could not find image: {img}")
image_parts = [
{
"mime_type": "image/png",
"data": Path("image0.png").read_bytes()
},
]
prompt_parts = [
"Is this suitable for someone on a Vegan diet?\n",
image_parts[0],
]
response = model.generate_content(prompt_parts)
print(response.text)That was sort of... effortless... No? We now have the necessary code that we can just paste into our app to integrate with Gemini Pro Vision. Obviously, this will need customizations to fit your specific use case and application logic. But hey, it's a great start!
If you look closely, you'll notice a placeholder YOUR_API_KEY which we'll need to replace with our API key.
Get your Gemini API key
Let's grab our API key by clicking on the "Get API key" menu item as shown in the screenshot below:
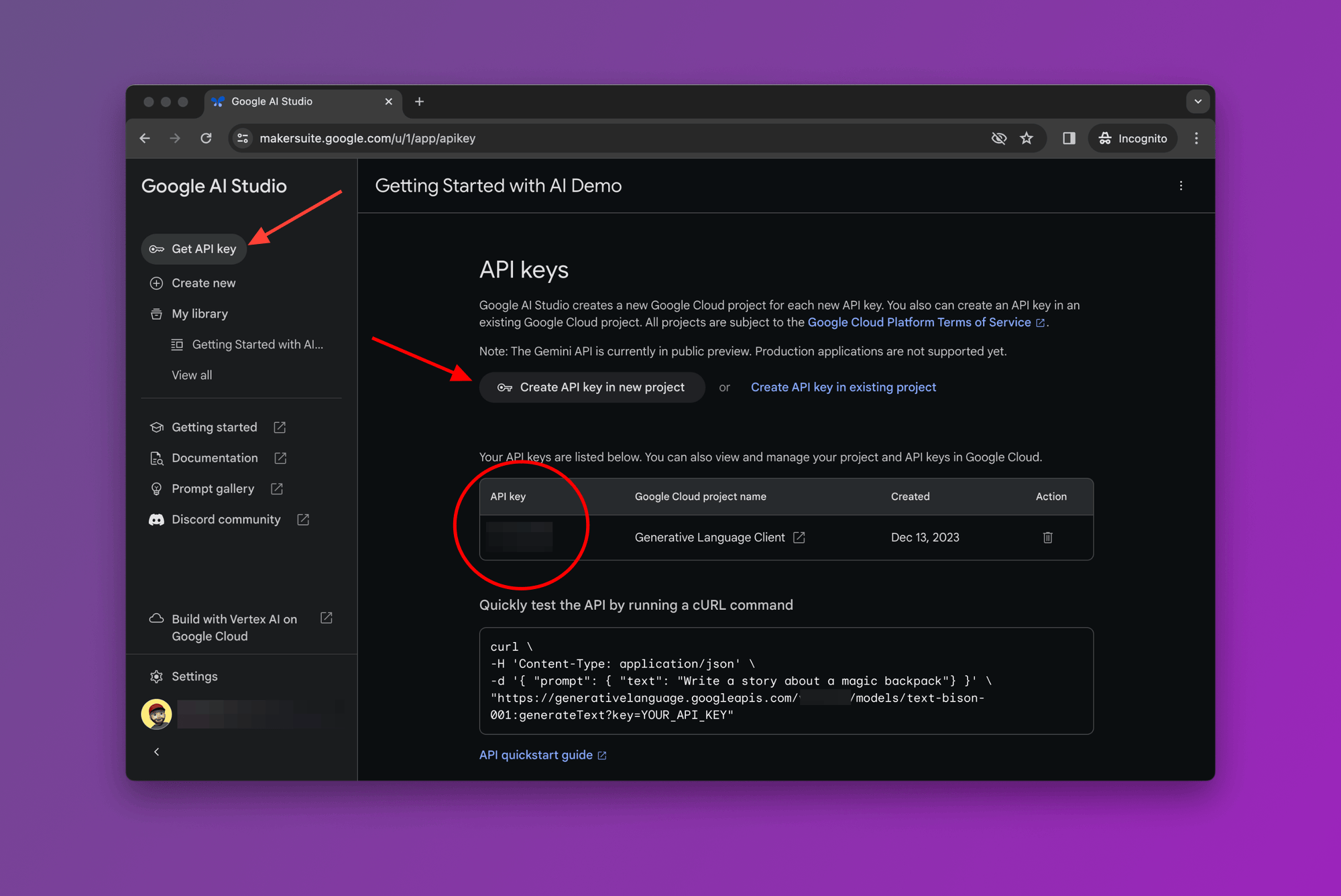
You can choose "Create API key in new project" or "Create API key in existing project".
After you create your API key, just add it to the code and you're ready to go!
Closing thoughts
Honestly, I am still playing around with Gemini Pro and Gemini Pro Vision. I somewhat still feel GPT-4 responds more naturally to some questions, however, I'm waiting to test the Ultra version which is coming out next year and as per Google, performs better than GPT-4.
As far as getting up and running with almost zero effort, Google AI Studio makes it really efficient for us to experiment and generate functional code that can be directly plugged into our apps.
In my opinion, it's one of the best prototyping tools out there.
FAQ: Frequently asked questions
What's the difference between Google AI Studio and Vertex AI
Think of Google AI Studio as a prototyping tool for developers and data scientists to interact and test Google's AI models, including Gemini. Vertex AI is an end-to-end machine learning platform that offers in-depth tools for model training and deployment. They both give us access to the latest Gemini models.